
티스토리 뷰
Basic Concepts
보편적으로 딥러닝 구조는 학습을 위해 이미 labeled된 많은 양의 학습데이터를 필요로 한다. 따라서 학습 데이터의 양이 부족하다는 것은 해당 딥러닝 모델의 성능이 좋지 않다는 것을 의미할 수 있다. Siamese Networks는 class당 적은량의 데이터만이 존재하거나 class별로 데이터 개수의 차이가 확연한 imbalanced class distribution의 상황에서도 예측의 정확성을 높히기 위해 고안되었다.
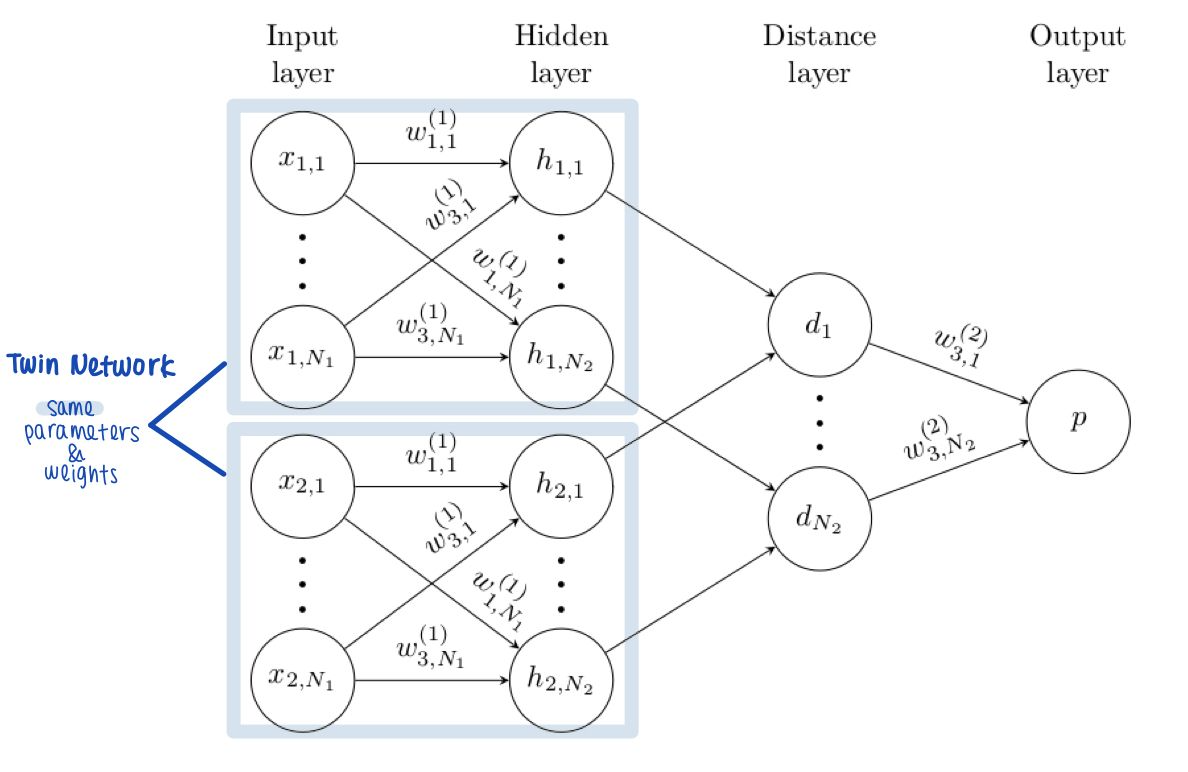
Sianmese Networks는 동일한 parameters나 weights을 갖는 쌍둥이, 즉 twin networks로 이루어져 있다. 이 twin networks는 한 쌍의 inputs을 받아 각자 받은 하나의 input의 features받아 두 inputs의 유사도를 계산한다. 이렇게 계산된 유사도를 이용하여 분류 문제에 적용할 수 있는데, 같은 class의 데이터들의 거리를 최소화하고 다른 classes에 속한 데이터들의 거리를 늘리는 방식으로 network를 학습시키는 것이다.
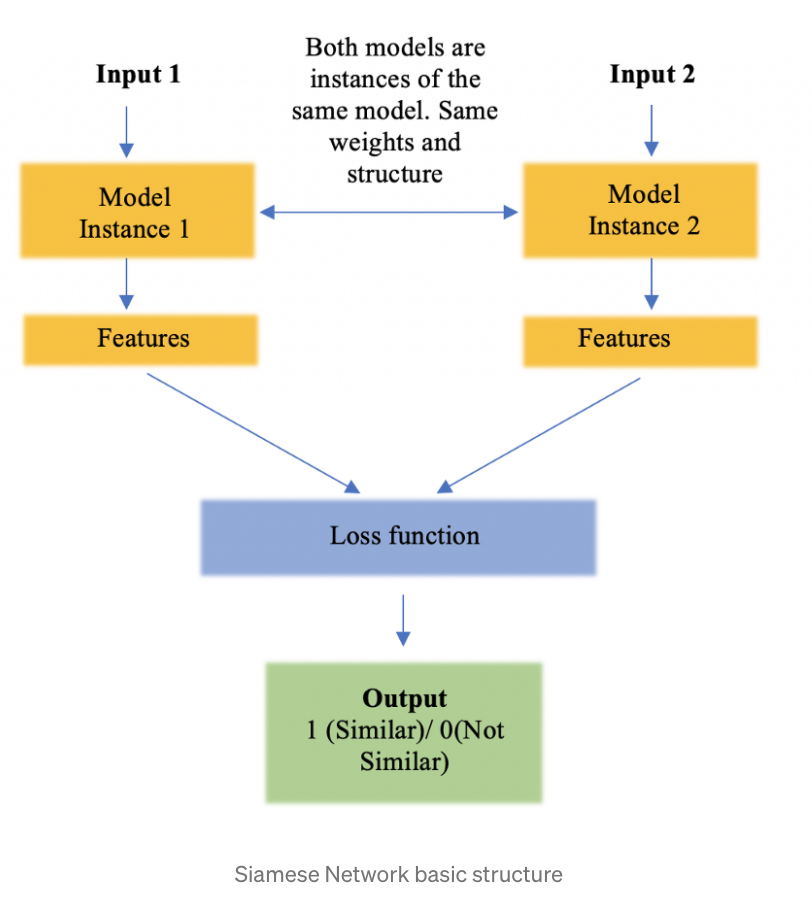
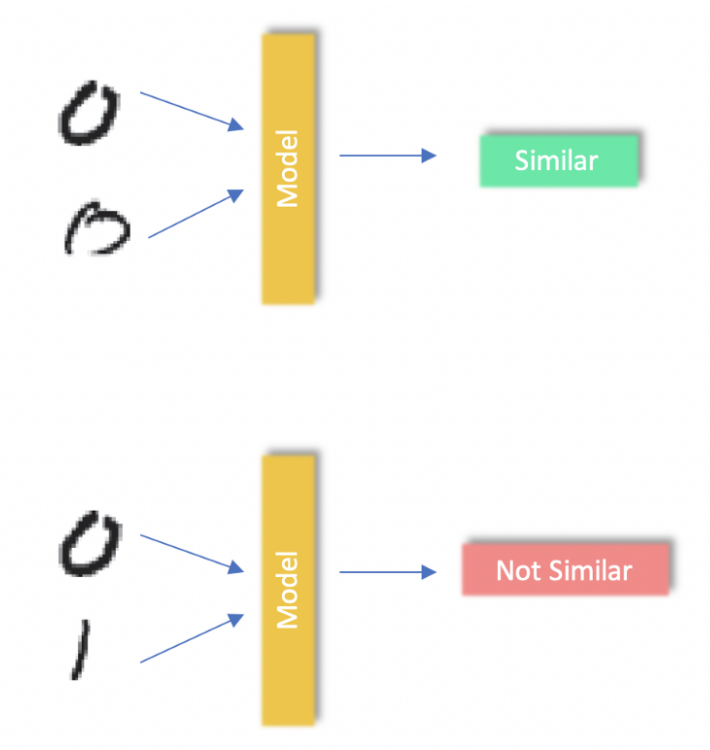
Loss Function 예시
1. Contrastive Loss
Binary Cross-Entropy가 가장 좋은 loss function 같긴 하지만 (Aditya Dutt의견) Contrastive Loss도 이미지 pairs사이의 다름을 구하는 데에 괜찮은 성능을 보인다.
$$ L = Y \cdot D^2 + (1-Y) \cdot \text{max}( \text{margin}-D, 0)^2 $$
- $D$: 이미지 features들 사이의 거리
- $\text{margin}$: 다른 classes로 데이터를 나누기 위한 parameter
2. Triplet Loss
Google에서 2015년 얼굴 인식 과제에서 소개한 Loss Function이다. 아래의 예시 이미지에서 Anchor가 reference input일 때, positive input은 anchor과 같은 클라스에, negative input은 anchor class와 다른 클라스에 랜덤으로 배정된다. Triple Loss Function의 기본 아이디어는 anchor 과 positive 샘플의 거리를 최소화하고 anchor과 negative 샘플의 거리를 최대화하는 것이다.

데이터 간의 distance metric을 $d$라고 할 때, anchor과 positive 샘플들의 거리가 anchor과 negative샘플들의 거리보다 가깝기 때문에 아래의 식으로 나타낼 수 있다.
$$ d(a,p) - d(a, n) <0 $$
그러므로 두 거리의 차를 최대화 하는 것이 Triplet Loss Function의 목표이므로 Loss, $L$, 는
$$ L = \text{max}(d(a,n)-d(a,p), 0) $$
또한, postive와 negative샘플의 seperation을 크게 하기 위해 $\text{margin}$이라는 parameter를 추가하면 최종적으로 Loss function은 아래와 같다.
$$ L = \text{max}(d(a,n) - d(a,p)+\text{margin}, 0) $$
Pros and Cons
앞서 서술했듯이 Siamese Networks의 장점은
- 각 class에 해당하는 데이터 개수가 적을 때에도 학습이 가능함
- 불균형한 데이터로도 학습이 가능함
그에 반해 단점은
- class당 데이터의 개수가 작을 때 학습이 가능할 지라도, 데이터의 pair를 input으로 받기 때문에 클라스당 데이터의 pair를 만들다보면 결국 training data의 개수는 많아질 수 있음
- 한 task에 쓰였던 model이 다른 tasks들에 활용되기 어려움 (not generalisable)
- input의 변형 데이터에 sensitive함
참고
- Siamese Neural Networks for One-Shot Image Recognition
https://www.cs.cmu.edu/~rsalakhu/papers/oneshot1.pdf - Siamese Networks Introduction and Implementation
https://towardsdatascience.com/siamese-networks-introduction-and-implementation-2140e3443dee
'머신러닝&딥러닝' 카테고리의 다른 글
| 인공지능 vs. 머신러닝 vs. 딥러닝 (0) | 2021.12.27 |
|---|---|
| Graph Convolutional Networks (GCN) (0) | 2021.12.15 |
| Graph Neural Network (GNN) (0) | 2021.12.09 |
| Transposed Convolution, Deconvolution & Upsampling (0) | 2021.03.05 |
| 파이토치를 활용한 Convolutional AutoEncoder - CIFAR-10 (1) | 2021.02.16 |
- Total
- Today
- Yesterday
- 재부팅
- 그래프
- unique value
- 윈도우
- Extrative_Summarisation
- GNN
- kernal error
- 딥러닝
- Summarisation
- NLP
- deep learning
- openCV기초
- np.ma.maked_where()
- Siamese Networks
- Python
- 합성곱
- 주피터노트북
- BERT
- 파이토치
- pytorch
- 폰트 사이즈 변경
- 논문구현
- Graph Neural Networks
- 오토인코더
- 파이썬
- 샴네트워크
- anaconda3
- ord()
- np.tri()
- 티스토리 코드 폰트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |